A model program aggregation describes the software component of a model within the water domain. It aims to fully describe the software-related metadata of a given model program to enable scientists to seamlessly retrieve all the content and information required to get a model up-and-running on their local or server-side machine. This aggregation consists of uploaded content such as source code, compiled binaries, and documentation, as well as metadata describing the model's software. The model program aggregation can be related to many model instance aggregations to completely describe a simulation and the exact software version used for a particular study to make data replication possible. Aggregation-level metadata describes this aggregation type.
When a composite resource containing a model program aggregation is downloaded as a Zipped BagIt Archive, the user finds that in the <ResourceID>/data/contents directory, in addition to the contents of model program aggregation, two additional files are also included, which hold the content type metadata (<AggregationName>_meta.xml and <AggregationName>_resmap.xml), where <AggregationName> is the name of the model program aggregation. If the model program aggregation from a single file or a folder containing one or more files. has a JSON schema, the same JSON schema would be also downloaded as <AggregationName>_schema.json.
Example
Model program aggregation can be created from a single file or a folder containing one or more files. The process for both file-based and folder-based model program aggregation is similar. Therefore, only the creation of a folder-based model program aggregation is described below. Please note that to create a file-based model program aggregation, the file added to a resource to become a model program aggregation should not create aggregation upon upload (e.g., do not use a NetCDF file creating a Multidimensional aggregation upon upload).
Folder-based model program aggregation:
One related file was added to a resource and placed in a folder called “SWAT Model Program”

This folder is converted to a model program by right clicking on the folder and selecting "Set content type -> Model Program".

The folder now appears in HydroShare as a model program content type using a model program symbol. Content specific metadata can then be added in the panel on the right side of the file browser interface. A standard set of metadata fields is available in the model program aggregation which can be used to describe/represent a specific model program (e.g., SWAT). This standard set of metadata includes general information (Title, Keywords, Coverage information, and Additional metadata (key/value)) as well as model program specific metadata (Name, Version, Release Date, Website, Code Repository, Operating Systems, Programming Languages, Content File Types). In addition, a metadata schema in JSON format can be used in a model program to define the metadata requirements of a corresponding model instance aggregation. When a model instance aggregation is linked to a model program aggregation using the 'executed_by' metadata field of the model instance, the metadata requirements of the model instance will be driven by the metadata schema of the linked model program. Both a standard set of metadata fields and the schema-based metadata fields in model instance aggregation can be used to represent a specific model instance (e.g., SWAT).
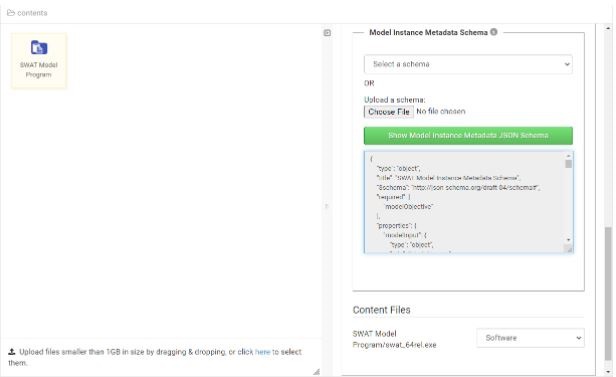
In the metadata field “Model Instance Metadata Schema”, the user can either select a JSON schema provided by HydroShare (currently only two schemas are provided: SWAT_Schema_1.0.0.json and MODFLOW_Schema_1.0.0.json) or upload a JSON file that has the metadata schema for the model instance aggregation which can be linked to this model program (linking a model instance to a model program is described here). The following figure shows a warning in red indicating that metadata schema is missing and provides the information on how to select/upload a metadata schema. The warning says "Metadata schema is missing. You can either upload a schema JSON file or select of the the existing schema JSON files. Save changes using the button below to make the uplaoded/selected schema JSON file part of the model program aggregation".

After selecting/uploading a JSON file when the metadata for a model program is saved, the JSON schema data on the form (read-only) can be displayed by clicking on the green button (“Show Model Instance Metadata JSON Schema”).
Notes on metadata schema:
- If the user wants to update the JSON schema, they must upload a new JSON file into the model program aggregation metadata.
- Although the uploaded/selected JSON schema file is not going to be part of the resource, the JSON schema will be available as a file in resource bag download or model program aggregation zip download.
- The values of metadata generated using JSON schema data areis also written to the aggregation metadata xml file (<AggregationName>_meta.xml) <AggregationName>_schema_values.json.
Other notes on model program aggregation:
- The user can see all metadata that they added to the model program aggregation in resource view mode.
- A model program aggregation can be also created inside a fileset aggregation.
- A model program aggregation can be created from a folder only if it has one or more files as long as there are no other aggregations inside that folder (no nested aggregation is supported).
- Other folders can be created inside a folder-based model program aggregation.
- If a file is uploaded to the folder or subfolder of a folder-based model program, that file becomes part of the model program. It is also possible to attach metadata to any single file that is part of the model instance aggregation.