A model instance aggregation defines the input and (optionally) the output data for a hydrological model for a specific time and place. A model instance aggregation consists of specific metadata to describe the model content as well as a reference to the model program aggregation that is used to execute a simulation. Aggregation-level metadata describes this aggregation type.
When a composite resource containing a model instance aggregation is downloaded as a Zipped BagIt Archive, the user finds that in the <ResourceID>/data/contents directory, in addition to the contents of model instance aggregation, two additional files are also included, which hold the content type metadata (<AggregationName>_meta.xml and <AggregationName>_resmap.xml), where <AggregationName> is the name of the model instance aggregation. If the model instance aggregation is linked to a model program aggregation that has a JSON schema via the 'executed_by' metadata field of the model instance, the same JSON schema would be also downloaded as <AggregationName>_schema.json. In this case, if there are populated metadata fields that are generated by the JSON schema, they are downloaded as a <AggregationName>_schema_values.json file.
Example
Model instance aggregation can be created from a single file or a folder containing one or more files. The process for both file based and folder based model instance aggregation is similar. Therefore, only the creation of a folder based model instance aggregation is described below. Please note that to create a file based model instance aggregation, the file added to a resource to become a model instance aggregation should not create aggregation upon upload (e.g., do not use a NetCDF file creating a Multidimensional aggregation upon upload).
Folder based model instance aggregation:
Two related files were added to a resource and placed in a folder called “Boyne River computational model.”

This folder is converted to a model instance by right clicking on the folder and selecting "Set content type -> Model Instance".

The folder now appears in HydroShare as a model instance content type using a model instance symbol. Content specific metadata can then be added in the panel on the right side of the file browser interface. A standard set of metadata fields is available in model instance aggregation which can be used to describe/represent a specific model instance. This standard set of metadata includes general information (Title, Keywords, Coverage information, and Additional metadata (key/value)) as well as model instance specific metadata (Includes Output Files, Model Program Used for Execution, and Schema Based Metadata only if the model instance is linked to a model program that has metadata schema).

In the metadata field 'Model Program Used for Execution', the user can select a model program aggregation from the dropdown menu showing all model program aggregations that are in the resource where the model instance is located (this guide shows how a model program aggregation can be created). Once a model program is selected for linking the model instance to it, the user must save the changes.

If the selected model program does not have a metadata schema, the warning "Selected model program is missing Metadata schema" is shown in red to alert the user.
Once the user provides a metadata schema for the linked model program or if the selected model program already has a metadata schema before linking a model instance to it, a green button is shown in the right side of the file browser interface of the model instance which can display the content of the metadata schema. Additionally, a new metadata editing form based on the schema definitions can be seen which is called “Schema Based Metadata”. The system generates this dynamically based on the JSON schema uploaded to the selected model program.
“Schema Based Metadata” is used to add metadata for the model instance. If all the metadata fields cannot be seen in the form, the user should click on the topmost 'Object properties' link and then check all the field names in the popup menu. Close the popup menu clicking again on the same 'Object properties' link. 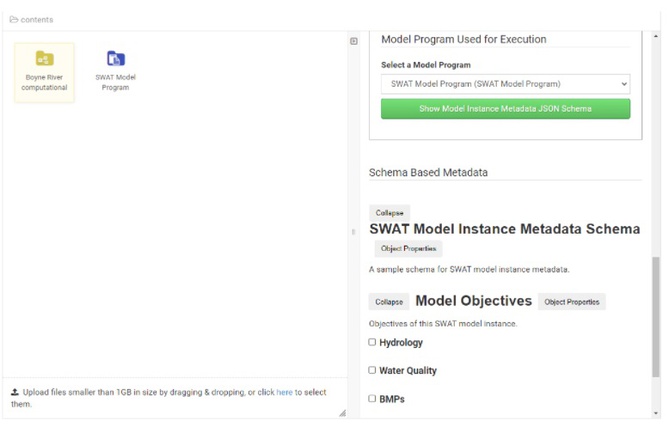
Notes on metadata schema:
- When a model instance is linked to a model program that has a metadata schema, the metadata schema gets copied into that model instance. This is only to make sure that if the model program is deleted, the associated metadata schema is not lost. However, if the user wants to edit the metadata schema itself, it can be only edited in the model program.
- Although the uploaded/selected JSON schema file is not going to be part of the resource, the JSON schema will be available as a file in resource bag download or model instance aggregation zip download.
- The values of metadata generated using JSON schema are written to <AggregationName>_schema_values.json.
Other notes on model instance aggregation:
- The user can see all metadata that they added to the model instance aggregation in resource view mode.
- A model instance aggregation can also be created inside a fileset aggregation.
- A model instance aggregation can be created from a folder only if it has one or more files including other aggregations and if the aggregations are not of type model instance, model program or fileset.
- If a file is uploaded to a folder-based model instance (or a subfolder of it), that file becomes part of the model instance. It is also possible to attach metadata to any single file that is part of the model instance aggregation.
Effect of Schema Changes on a Model Instance Linked to the Model Program and the Schema-based Metadata in the Model Instance

After schema-based metadata has been added to a model instance, if a user changes schema used for the linked model program, the existing model instance schema-based metadata may or may not be valid anymore against the new schema. If the added schema based metadata is still valid against the new schema, after selecting the model instance in the edit mode, the user will notice that a blue button appears which enables the user to “Update Metadata Schema from Model Program”. The blue button to copy the metadata schema from model program over to the model instance is a safe update – no loss of metadata happens in model instance. One example of this case is when a user edits an existing JSON schema by adding a new attribute that is NOT set to be ‘required’. Note, the option to copy (update) the schema of the model instance will appear only if the schema in the model program is different from the model instance.
If the linked model program has a schema that invalidates the existing metadata in a model instance, the metadata panel for model instance aggregation will look as follows (with the option to update/copy schema – the red button). The red button to copy the metadata schema from model program over to the model instance is NOT a safe update – it will result in loss of metadata in model instance. a message will appear above the button that says "Metadata schema in the associated model program fails to validate existing metadata. Updating the schema from the model program will lead to loss of all schema based metadata in this model instance". One example of this case is when a user edits an existing JSON schema by removing an attribute that already has a value.

SWATShare Web Service for SWAT Model Instances
Please note that using the “Open with” button at the top of the Resource Landing Page and selecting the SWATshare web service to explore the model instance “aggregations” linked to a SWAT model program aggregation is NOT enabled yet. However, the obsolete SWAT model instance “resources” can benefit from this functionality. In the near future, HydroShare will migrate all model resources to aggregations, enable this functionality for the model instance aggregations of SWAT, and provide the guide on how to enable using SWATShare for the model instance aggregations of SWAT.
A SWATShare web service enables interoperability between HydroShare and SWATShare by letting users run and visualize SWAT model instances that are stored in HydroShare.
The obsolete SWAT model instance resources can be explored in SWATShare by clicking on the “Open with” button at the top of the Resource Landing Page and selecting the SWATShare web service.

As mentioned above, a guide on how to use SWATShare Web Service to explore model instance aggregations of the SWAT model will be provided once this functionality is added.
A SWATshare web service enables interoperability between HydroShare and SWATShare by letting users to run and visualize SWAT model instances that are stored in HydroShare.
The obsolete SWAT model instance resources, can be explored in SWATshare by clicking on the “Open with” button at the top of the Resource Landing Page and selecting the SWATshare web service.
As mentioned above, a guide on how to use SWATShare Web Service to explore model instance aggregations of the SWAT model will be provided once this functionality is added.